가상탐색을 위한 단백질 구조 선정 방법


이전 글에서는 구조 기반 신약 개발 연구(SBDD) 과정에서 binding site를 정의 할 때 고려하면 좋을 사항들에 대해 다루었습니다. 이번 글에서는 self-docking과 cross-docking을 활용해 가상탐색을 위한 표적 단백질의 구조 (conformation) 선택 과정을 다뤄 보겠습니다.
가상 탐색
가상탐색은 수십만에서 수십억 개의 디지털 화합물 라이브러리에서 다양한 조건을 만족하는 소수(보통 수백 개)의 화합물을 선택합니다. 그리고 이들을 실제 실험으로 검증해서 신약 개발이 가능한 유효물질들을 찾는 것을 목적으로 합니다. 화합물 라이브러리의 선택 또한 매우 중요한 항목이지만, 이는 다른 글에서 다루겠습니다.
화합물을 선택하기 위한 조건들은 목적에 따라 다양하게 사용할 수 있습니다. 보통 빠르게 계산할 수 있는 Lipinski’s rule 등의 항목을 앞쪽에 두곤 합니다. 물론 뒤로 갈수록 계산 비용은 높아지지만 신뢰도가 높은 조건들을 배치하게 됩니다.

단백질 약물 결합 구조 방식
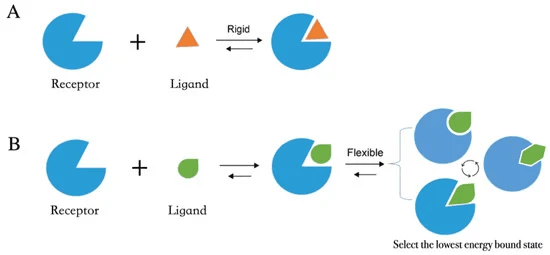
단백질 - 약물을 결합하는 방식에는 두 가지 모델이 있습니다.
단백질 약물 결합 구조 방식 1. Lock and key
우선 “Lock and Key” 모델이 있습니다. Lock and Key 모델은 단백질이 약물을 받아들일 수 있게끔, 이미 결정된 binding site 구조를 가지고 있다고 가정한 채 진행됩니다. 마치 자물쇠에 꼭 맞는 열쇠가 있어서, 자물쇠를 열거나 잠글 수 있는 것과 유사합니다. 상단의 그림을 참고하시면 더욱 이해가 쉬울 것입니다.
단백질 약물 결합 구조 방식 2. Induced fit
이 모델에 단백질의 유동성이라는 중요한 성질을 반영하여 “Induce Fit” 모델이 나왔습니다. Induced fit 모델에 따르면 단백질과 약물은 상호작용을 통해 서로의 구조적 변화를 유도하고 에너지 적으로 안정된 결합 구조를 이루게 됩니다. 여기에서 더 나아가 단백질의 다양한 구조 중 가장 궁합이 잘 맞는 구조와 결합합니다. 이를 안정화하는 모델인 “Conformational Selection and Population Shift” 모델이 널리 받아들여지고 있습니다.
다행히도 우리는 ‘단백질과 약물이 어떻게 안정적인 결합 구조를 이루는가?’에 대해 정확하게 알 필요는 없습니다. 우리가 집중해야 할 질문은 “그래서 어떤 단백질 구조를 써야 하지?” 입니다. 이제 다시 구조 기반의 가상탐색으로 돌아가 보겠습니다.
도킹(Docking)
“그래서 어떤 단백질 구조를 써야 하지?” 와 같은 선택은 도킹(docking)을 수행하기 위한 시작이자 핵심이 되는 과정입니다. Docking은 단백질과 약물의 결합 구조를 예측하기 위한 방법임과 동시에 구조 기반 신약 개발 연구의 시작점이라 할 수 있습니다.
도킹(Docking)이란?
신약 개발에서 도킹은 분자 수준에서의 상호 작용을 분석하고 이해하는 데 사용되는 컴퓨터 기반의 기술입니다. 보통 분자 구조를 모델링하여, 특정 분자와 다른 분자 간의 상호 작용이 어떻게 이루어지는지 예측하고 이해하는 데 활용됩니다. 이를 통해 신약 후보물질이 특정 단백질이나 타겟에 결합하는 방식을 이해하고, 이를 기반으로 효과적인 약물 디자인 및 최적화에 기여할 수 있습니다.
도킹(Docking)을 위해 한 개 이상의 단백질 구조를 선택하는 과정에서 올바른 의사 결정을 위해 어떤 정보들을 활용 할 수 있는지 살펴보겠습니다. 가장 이상적인 실험 환경에서 실제 가상탐색 환경으로 점점 변수들을 추가한다고 생각하시면 이해에 도움이 될 것 같습니다.
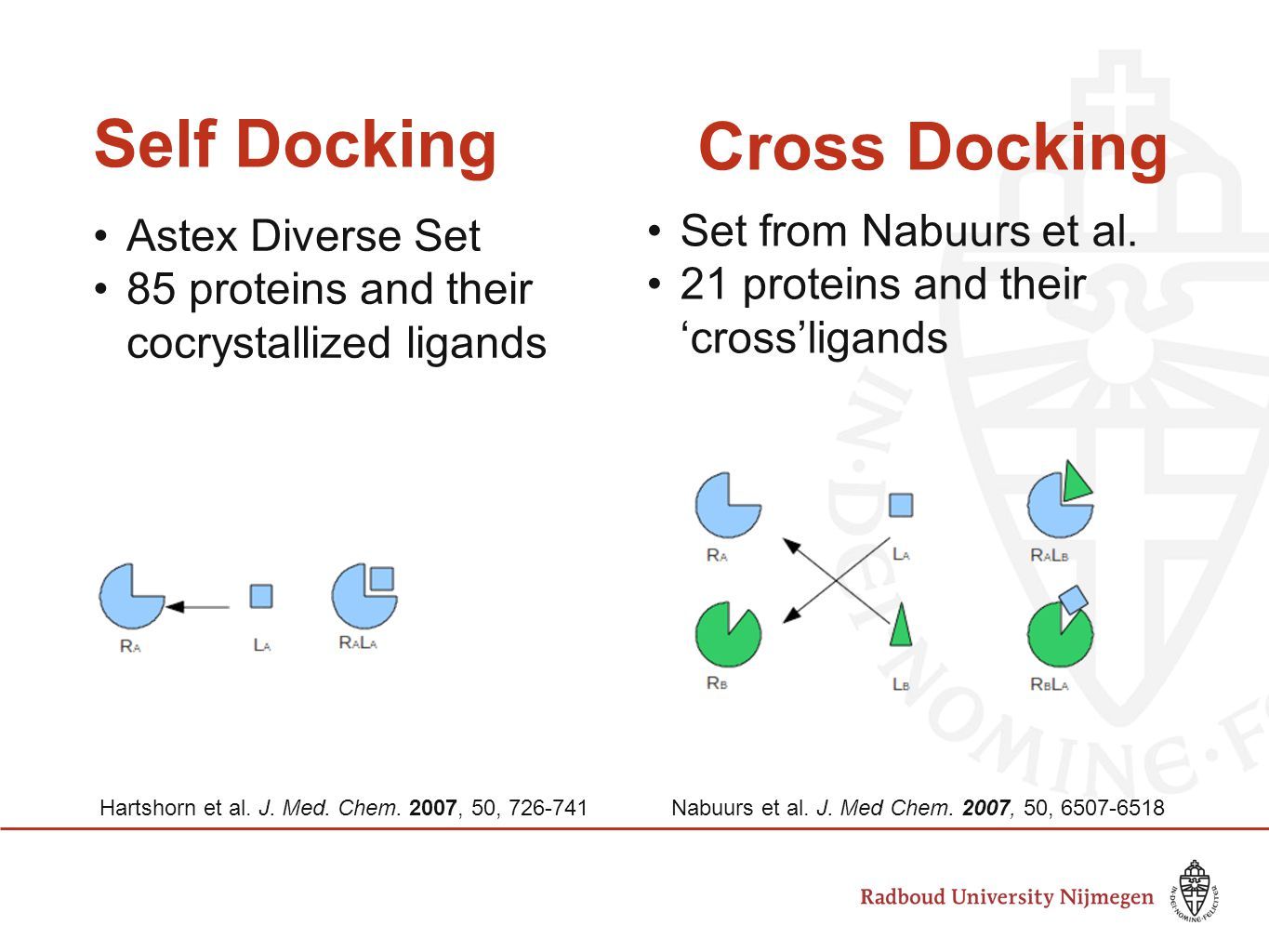
셀프 도킹(Self-Docking)
Self-docking은 단백질-약물 x-ray 결합 구조에서 약물을 떼어낸 후 도킹(docking)으로 x-ray 구조를 재현할 수 있는지 확인하는 과정입니다. 셀프 도킹(Self-docking)을 가장 먼저 하는 이유는 가장 이상적인 환경이기 때문입니다. 단백질-약물 x-ray 결합 구조는 실험으로 결정된 구조이기 때문에 구조에서 오는 오류가 최소인 조건이라고 할 수 있습니다. 만약 셀프 도킹(Self-docking)으로 x-ray 구조가 재현 되지 않는다면 다음 항목들을 검토해 보아야 합니다. 보통 약물의 실험과 도킹(docking) 구조의 RMSD가 2Å 이내라면 결합 구조를 잘 예측했다고 평가합니다.
- 단백질 구조, 특히 binding site를 살펴봐야 합니다. 실험 결과라고 해서 문제가 전혀 없는 건 아닙니다. 이전 글에서 alternative conformation에 대해 알아 보았습니다. 존재 가능성(occupancy)이 가장 높은 residue를 선택하면 대부분 별다른 문제가 없지만 드물게 (특히 occupancy가 비슷한 경우) 존재 가능성이 2번째 이하인 conformation이 올바른 경우들이 있으니 확인이 필요합니다. 또 다른 가능성은 x-ray 결과의 해상도 (resolution) 문제 입니다. X-ray는 역동적으로 움직이는 단백질 구조의 snapshot이라고 할 수 있습니다. 이 때, ‘역동적 구조를 얼마나 정밀하게 측정 했는가’를 나타내는 지표가 resolution입니다. 보통 resoultion이 2Å 이내이면 큰 문제가 없지만 그 이상이라면 아미노산 residue와 약물 사이가 너무 가까워 충돌하는 등의 문제가 있을 수 있습니다. 이런 경우 MD simulation을 통해 구조를 최적화 하거나 다른 구조를 선택하는 등, 다양한 선택이 가능합니다. 한 PDB 파일에 동일한 단백질-약물 결합 구조가 두 개 이상인 경우 구조의 크고 작은 차이가 있을 수 있습니다. 이들 모두를 실험해 보는 것도 한 가지 방법 입니다.
- 구조적으로 문제가 없을 경우 도킹(docking) 알고리즘이나 option 설정을 검토해 볼 필요가 있습니다. 셀프 도킹(Self-docking)으로 x-ray 구조가 재현되지 않는다면 binding site의 크기를 줄이거나 exhaustiveness (thoroughness)를 높이는 등 설정을 바꿔서 실험해 볼 수 있습니다.
하이퍼랩은 다양한 실험을 통해 최적화된 docking 환경을 제공하고 있습니다. 또한 정확성이 매우 개선된 자체 도킹(docking) 알고리즘인 ES 방법을 2024년, 올해 제공할 예정입니다.
크로스 도킹(Cross-Docking)
크로스 도킹(Cross-docking)은 단백질A-약물B 결합 구조에서 약물B를 떼서 단백질A-약물C 결합 구조의 단백질A에 docking하여 약물B의 결합 구조를 재현할 수 있는지 확인하는 과정입니다. 크로스 도킹(Cross-docking)은 셀프 도킹(self-docking)에 비해 단백질 구조라는 변수가 추가된 실험 환경입니다. 실제 가상 탐색에서는 결합 구조가 알려져 있지 않은 다양한 화합물들을 사전에 선택한 단백질 구조에 docking해야 합니다. 그래서 실제 상황에 보다 가까운 조건이라고 할 수 있습니다. Cross-docking은 목적은 바로 이 가상 탐색에 사용할 소수의 단백질 구조를 선택하는 것 입니다. 단백질 구조는 1개 이상을 선택하게 되며, 2개 이상의 단백질 구조를 선택하여 다양한 단백질 구조 (conformation)을 반영하는 경우는 ensemble docking이라고 합니다.

상단의 그림은 CK1 delta 23개 PDB 구조에 대한 크로스 도킹(cross-docking) 결과 입니다.(10.3389/fmolb.2022.909499). X, Y 축은 각각 ligand와 단백질입니다. X 축 레이블은 PDB code-ligand code 입니다. 오른쪽 컬러 바는 ligand의 x-ray-docking 구조의 RMSD로 0에 가까울수록, 즉 진한 파란색일수록, 정확하다고 할 수 있습니다. 만약 모든 단백질들의 구조가 서로 너무 달라서 docking으로 ligand의 x-ray 결합 구조를 재현할 수 없다면, 대각선(self-docking)을 제외하고는 모두 붉은 색일 겁니다. 반대로 단백질 구조들이 매우 비슷해서 어떤 단백질을 사용해도 ligand x-ray 구조가 잘 재현 된다면 모두 파란색일 겁니다. 아래 그림에서는 파란색도 있고 빨간색도 있습니다. 그렇다면 우리는 어떤 단백질 구조를 선택해야 할까요?
- 우선 파란색이 많은, 즉 다양한 ligand의 결합 구조가 잘 재현 되는 단백질 구조를 고릅니다. 저는 이런 단백질을 대표성이 있다고 표현합니다.
- 하나의 단백질로 대부분의 ligand의 결합 구조를 잘 예측할 수 있다면 이대로 마무리 해도 되겠지만 그렇지 않을 경우에는 다른 단백질 구조를 추가로 고려해 볼만 합니다. 이때는 최소한의 단백질 구조로 최대한 많은 ligand를 처리할 수 있는 조합을 찾는 것이 좋습니다. 무작정 많은 단백질을 선택한다면 계산 시간이 이에 비례해서 늘어날 뿐더러 잘못된 결합 구조가 폭발적으로 늘어날 우려가 있습니다. (탐색해야 할 화합물이 적어도 몇십만 개라는 걸 잊지 마세요!) 보통 도킹(docking)은 한 단백질-ligand 조합 당 10개 정도의 결합 구조를 제공합니다. 이중 하나를 제외하고 정답이 없을 경우는 모두 잘못된 결합 구조입니다. 상단 그림에서는 4KBB-B와 6RCH를 선택하면 4HNF-16W를 제외하곤 모두 2Å 이내로 예측 가능함을 알 수 있습니다.
셀프 도킹과 크로스 도킹을 넘어 올바른 단백질 구조 선택까지
물론 이렇게 단백질 구조를 선택한다 해도 화합물 라이브러리에 있는 모든 화합물의 결합 구조를 정확히 예측 할 수 있는 것은 아닙니다. 우리가 활용 할 수 있는 정보는 한정되어 있고 화합물 공간(Chemical space)은 이와는 비교 할 수 없이 넓으니까요! 이러한 선택 과정은 현재 가지고 있는 정보를 최대한 활용하고 보다 나은 결과를 얻기 위함입니다. 셀프 도킹(Self-docking)과 크로스 도킹(cross-docking)은 올바른 단백질 구조를 준비하기 위한 과정의 일부 입니다. 다음 글에서는 핵심 단백질-약물 상호작용 분석과 활성 예측 과정을 다루도록 하겠습니다.